
Literature Reading ———— Conformer
Conformer

摘要
在卷积神经网络(CNN)中,卷积运算擅长提取局部特征,但难以捕捉全局表示。在visual transformer中,级联的自注意力模块可以捕获远距离特征依赖,但是会损失局部特征细节。在本文中,我们提出了一种混合网络结构,称为Conformer,以利用卷积运算和自注意机制来增强表示学习。Conformer源于特征耦合单元(FCU),它以交互方式融合不同分辨率下的局部特征和全局表示。Conformer采用并发结构,以便最大程度地保留局部特征和全局表示。
实验表明,在参数复杂度相当的情况下,Conformer在ImageNet上的性能优于visual transformer(DeiT-B)2.3%。在MSCOCO上,它在对象检测和实例分割方面分别比ResNet-101高出3.7%和3.6%,显示了作为通用主干网络的巨大潜力。代码可在github.com/pengzhiliang/Conformer获得。
前言
卷积神经网络(CNNs)能够处理非常先进的计算机视觉任务,如图像分类、对象检测和实例分割。这在很大程度上归功于卷积运算,它以分层的方式获取局部特征作为强大的图像表示。尽管CNN在局部特征提取上具有优势,但在捕捉全局表示(例如,视觉元素之间的长距离关系)方面存在困难,这对于高级计算机视觉任务来说通常是至关重要的。
最近,transformer架构已经被引入到视觉任务中。ViT方法通过将每个图像分割成具有位置嵌入的小块来构造标记序列,并应用级联transformer块来提取参数化向量作为视觉表示。由于自注意力机制和多层感知器(MLP)结构,ViT反映了复杂的空间转换和长距离特征依赖,这构成了全局表示。不过,ViT被发现其忽略了局部特征细节,这降低了背景和前景之间的可分辨性,图1(c)和(g)。改进的ViT已经提出了标记化模块或者利用CNN特征图作为输入标记来捕获特征邻近信息。然而,如何精确地将局部特征和全局表示相互嵌入的问题仍然存在。
在本文中,我们提出了一种双重网络结构,称为Conformer,旨在将基于CNN的局部特征与基于transformer的全局表示相结合,以增强表示学习。Conformer由一个CNN分支和一个transformer分支组成,分别遵循ResNet和ViT的设计。这两个分支形成了局部卷积块、自注意力模块和MLP单元的综合组合。在训练期间,交叉熵损失被用于监督CNN和transformer分支,以耦合CNN类型和transformer类型的特征。
考虑到CNN和transformer特征之间的特征不一致性,我们设计了特征耦合单元(FCU)作为桥梁。一方面,为了融合两种类型的特征,FCU利用1×1卷积来对齐通道维度,下/上采样策略来对齐特征分辨率,LayerNorm和BatchNorm来对齐特征值。另一方面,由于CNN和transformer分支倾向于捕捉不同级别的特征(例如,局部和全局),FCU被插入到每个块中,以交互方式连续消除它们之间的语义差异。这种融合过程可以极大地增强局部特征的全局感知能力和全局表示的局部细节。
图1展示了Conformer耦合局部特征和全局表示的能力。虽然传统的CNN(例如,ResNet-101)倾向于保留有区别的局部区域(例如,孔雀的头部或尾部),但Conformer的CNN分支可以激活整个对象范围,图1(b)和(f)。当单独使用transformer时,对于弱的局部特征(例如,模糊的对象边界),很难将对象与背景区分开,图1(c)和(g)。局部特征和全局表示的耦合显著增强了基于transformer的特征的可辨别性,图1(d)和(h)。
本文的贡献包括:
- 我们提出了一种双重网络结构,称为Conformer,它最大限度地保留了局部特征和全局表示。
- 我们提出了特征耦合单元(FCU),以交互方式将卷积局部特征与基于transformer的全局表示融合。
- 在可比较的参数复杂性下,Conformer明显优于CNN和visual transformers。Conformer继承了CNN和visual transformers的结构和泛化优势,展示了成为通用骨干网络的巨大潜力。
相关工作
Conformer介绍
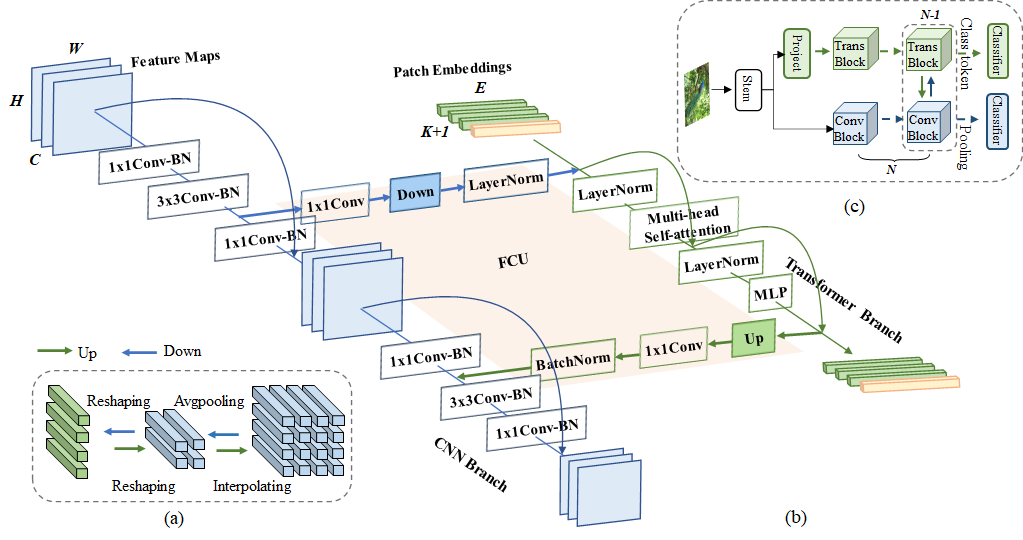
总览
局部特征和全局表征两个都很重要,在视觉描述符的漫长历史中被广泛研究。局部特征及其描述符[33,26,34]是局部图像邻域的紧凑矢量表示,已经成为许多计算机视觉算法的构建模块。全局表示包括但不限于轮廓表示、形状描述符和远距离对象类型[31]。在深度学习时代,CNN通过卷积运算以分层的方式收集局部特征,并将局部线索保留为特征图。视觉转换器被认为通过级联的自关注模块以软方式在压缩的补丁嵌入中聚集全局表示。
实验
结论
 wechat
wechat alipay
alipay

