No title
some examples
.numpy()
官方文档:https://pytorch.org/docs/stable/tensors.html#torch.Tensor.numpy
功能:将张量转换为与其共享底层存储的 n 维 numpy 数组
.item()
官方文档:torch.Tensor - PyTorch 1.11.0 documentation
功能:将张量的值转换为标准的 Python 数值,只有当张量仅含一个元素时才能使用它
.detach()
官方文档:Automatic differentiation package - torch.autograd
功能:返回一个与当前 graph 分离的、不再需要梯度的新张量
.cuda()
官方文档:https://pytorch.org/docs/stable/tensors.html#torch.Tensor.cuda
功能:将张量拷贝到 GPU 上
.cpu()
官方文档:torch.Tensor - PyTorch 1.11.0 documentation
功能:将张量拷贝到 CPU 上
分组卷积和深度可分离卷积
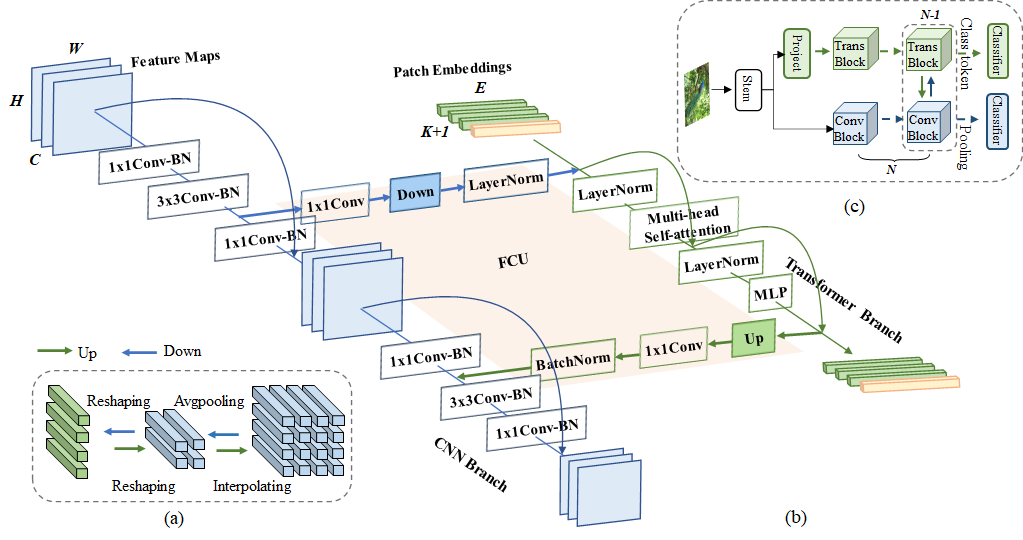
MobileNetV2
参数图示
t : 升维的扩张倍数
c : 输出通道数
n : bottleneck 的次数
s : 卷积核移动步长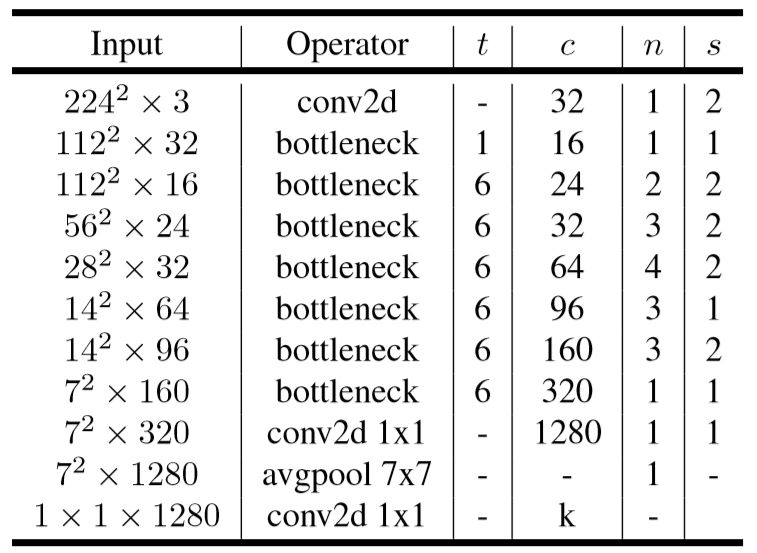
Inverted residuals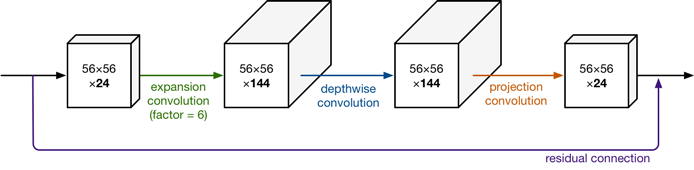
整个网络是中间胖,两头窄,像一个纺锤形。
在projection convolution这一部分,我们不再使用ReLU激活函数而是使用线性激活函数。
下面谈谈为什么要构造一个这样的网络结构。
我们知道,如果tensor维度越低,卷积层的乘法计算量就越小。那么如果整个网络都是低维的tensor,那么整体计算速度就会很快。
然而,如果只是使用低维的tensor效果并不会好。如果卷积层的过滤器都是使用低维的tensor来提取特征的话,那么就没有办法提取到整体的足够多的信息。所以,如果提取特征数据的话,我们可能更希望有高维的tensor来做这个事情。V2就设计这样一个结构来达到平衡。
先通过Expansion layer来扩展维度,之后在用深度可分离卷积来提取特征,之后使用Projection layer来压缩数据,让网络重新变小。因为Expansion layer 和 Projection layer都是有可以学习的参数,所以整个网络结构可以学习到如何更好的扩展数据和从新压缩数据。
depthwise convolution
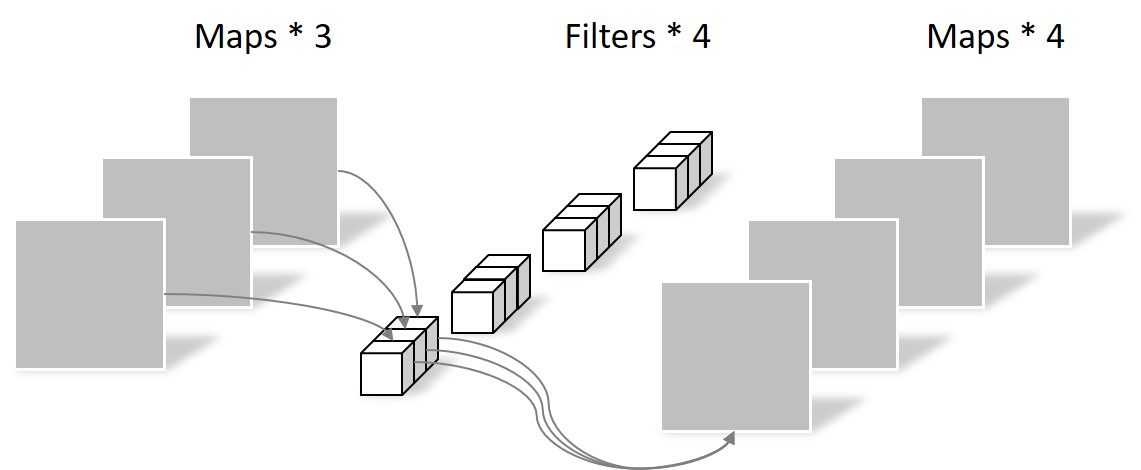
input.shape = [c1, H, W] output.shape = [c2, H, W]
(a)常规卷积参数量=kernel_size kernel_size c1 c2
(b)深度可分离卷积参数量=kernel_size kernel_size c1 + 1 1c1 c2
深度可分离卷积进行一次卷积是无法达到输出指定维度的tensor的,这是由它将group设为in_channel决定的,输出的tensor通道数只能是in_channel,不能达到要求,所以又用了11的卷积改变最终输出的通道数。这样的想法也是自然而然的,BottleNeck不就是先11卷积减少参数量再33卷积feature map,最后再11恢复原来的通道数,所以BottleNeck的目的就是减少参数量。提到BottleNeck结构就是想说明1*1卷积经常用来改变通道数。
 wechat
wechat alipay
alipay